Chapter 11 Tidy data
“Order and simplification are the first steps toward the mastery of a subject.”
— Thomas Mann
“Get your facts first, and then you can distort them as much as you please.”
— Mark Twain
The Tidyverse is a collection of R packages that adhere to the tidy data principles of data analysis and graphing. The purpose of these packages is to make working with data more efficient. The core Tidyverse packages were created by Hadley Wickham, but over the last few years other individuals have added some packages to the collective, which has significantly expanded our data analytical capabilities through improved ease of use and efficiency. The Tidyverse packages can be loaded collectively by calling the tidyverse package, as we have seen throughout this workshop. The packages making up the Tidyverse are shown in Figure 11.1.
Figure 11.1: The Tidyverse by Hadley Wickham and co.
library(tidyverse)As we may see in the following figure (Figure 11.2), the tidying of ones data should be the second step in any workflow, after the loading of the data.
](figures/data-science-wrangle.png)
Figure 11.2: Data tidying in the data processing pipeline. Reproduced from R for Data Science
But what exactly are tidy data? It is not just a a buzz word, there is a real definition. In three parts, to be exact. Taken from Hadley Wickham’s R for Data Science:
- Each variable must have its own column—i.e. each of the things known about the data in its own column.
- Each observation must have its own row—each of the things measured in its own row; for example, in the Laminaria data the measured things include
blade_length,blade_weight, etc., and they can all be captured in one column named, for example,measurement.
- Each value must have its own cell—each of the things that is known and measured must be in its own cell.
This is represented graphically in F 11.3. One will generally satisfy these three rules effortlessly simply by never putting more than one dataset in a file, and never putting more (or less) than one variable in the same column. We will go over this several more times today so do not fret if those guidelines are not immediately clear.
](figures/tidy-1.png)
Figure 11.3: Following three rules make a dataset tidy — variables are in columns, observations are in rows, and values are in cells. Reproduced from R for Data Science
In order to illustrate the meaning of this three part definition, we are going to learn how to manipulate a non-tidy dataset into a tidy one. To do so we will need to learn a few new, very useful functions. Let’s load our demo dataset to get started. This snippet from the SACTN dataset contains only data for 2008-2009 for three time series, with some notable (untidy) changes. The purpose of the following exercises is not only to show how to tidy data, but to also illustrate that these steps may be done more quickly in R than MS Excel, allowing for ones raw data to remain exactly how they were collected, with all of the manipulations performed on them documented in an R script. This is a centrally important part of reproducible research.
load("data/SACTN_mangled.RData")With our data loaded let’s now have a peek at them. We will first see that we have loaded not one, but five different objects into our environment pane in the top right of our RStudio window. These all contain the exact same data in different states of disrepair. As one may guess, some of these datasets will be easier to use than others.
SACTN1
SACTN2
SACTN3
# Spread across two dataframes
SACTN4a
SACTN4bWe start off by looking at SACTN1. If these data look just like all of the other SACTN data we’ve used thus far that’s because they are. These are how tidy data should look. No surprises. In fact, because these data are already tidy it is very straightforward to use them for whatever purposes we may want. Making a time series plot, for example.
ggplot(data = SACTN1, aes(x = date, y = temp)) +
geom_line(aes(colour = site, group = paste0(site, src))) +
labs(x = "", y = "Temperature (°C)", colour = "Site") +
theme_bw()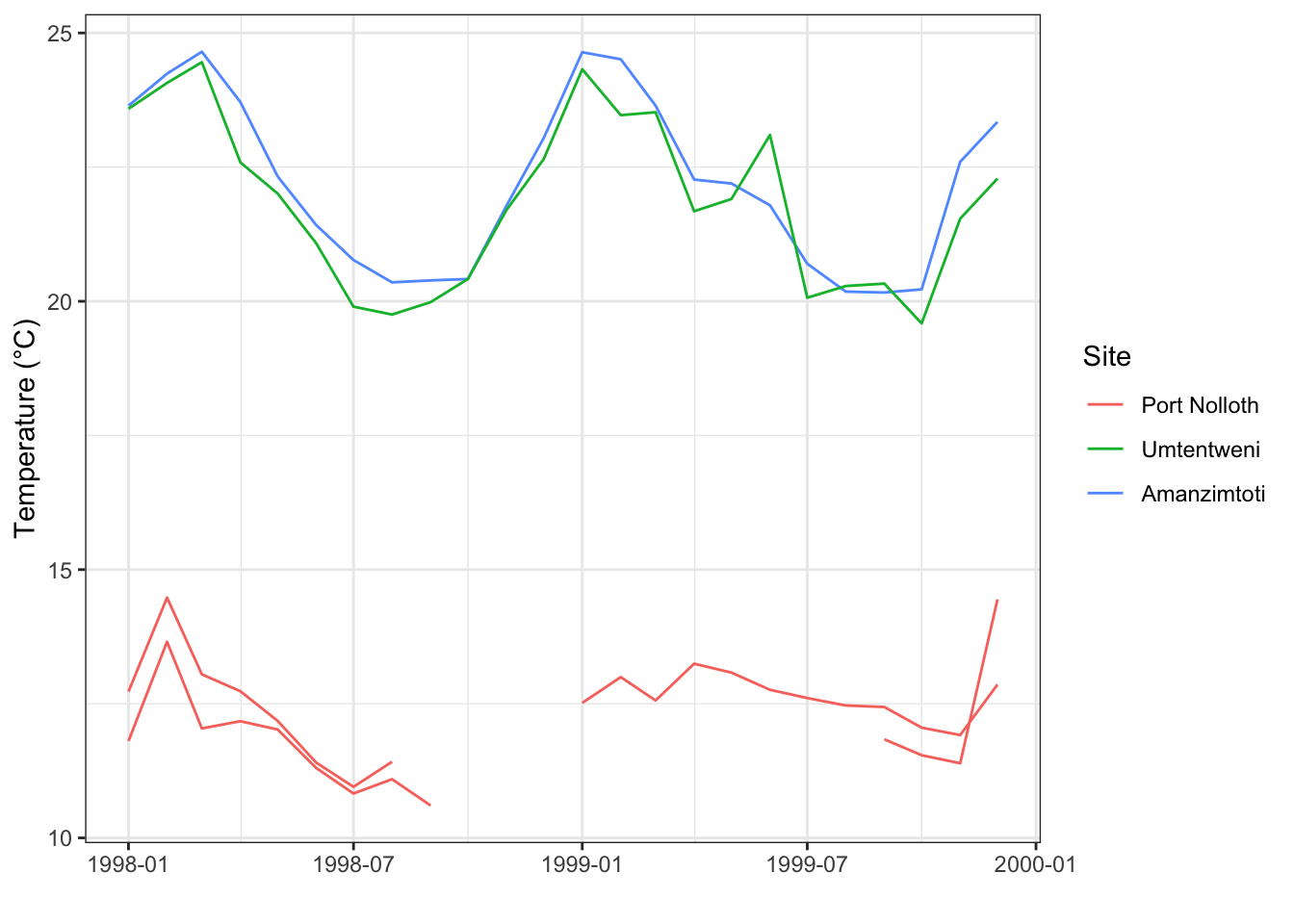
%>%
Remember that this funny series of symbols is the pipe operator. It combines consequetive rows of code together so that they run as though they were one ‘chunk.’ We will be seeing this symbol a lot today. The keyboard shortcut for%>%is ctrl-shift-m.
11.1 Gathering and spreading
Before tidy became the adjective used to describe neatly formatted data, people used to say long. This is because well organised dataframes tend to always be longer than they are wide (with the exception of species assemblage data). The opposite of long data are wide data. If one ever finds a dataset that is wider than it is long then this is probably because the person that created them saved one variable across many columns.
As we sit here and read through these examples it may seem odd that so much effort is being spent on something so straightforward as tidy data. Surely this is too obvious to devote an entire day of work to it? Unfortunately not. As we go out into the wild world of ‘real life data,’ we tend to find that very few datasets (especially those collected by hand) are tidy. Rather they are plagued by any number of issues. The first step then for tidying up the data are to have a look at them and discern what are the observations that were made/recorded (the ‘measurements’), and what are the variables within those observations. We also need to know something about how or where the data were collected, or what threy represent — this is information about the data, i.e. some meta-data. Let’s have a look now at SACTN2 for an example of what wide data look like, and how to fix it.
11.1.1 Gathering
In SACTN2 we can see that the src column has been removed and that the temperatures are placed in columns that denote the collecting source. This may at first seem like a reasonable way to organise these data, but it is not tidy because the collecting source is one variable, and so should not take up more than one column. We need to gather() these source columns back together. We do this by telling gather() what the names of the columns are we want to squish together. We then tell it the name of the key column. This is the column that will contain all of the old column names we are gathering. In this case we will call it src. The last piece of this puzzle is the value column. This is where we decide what the name of the column will be for values we are gathering up. In this case we will name it temp, because we are gathering up the temperature values that were incorrectly spread out by month.
SACTN2_tidy <- SACTN2 %>%
gather(DEA, KZNSB, SAWS, key = "src", value = "temp")11.1.2 Spreading
Should ones data be too long, meaning when individual observations are spread across multiple rows, we will need to use spread() to rectify the situation. This is generally the case when we have two or more variables stored within the same column, as we may see in SACTN3. This is not terribly common as it would require someone to put quite a bit of time into making a dataframe this way. But never say never. To spread data we first tell R what the name of the column is that contains more than one variable, in this case the ‘var’ column. We then tell R what the name of the column is that contains the values that need to be spread, in this case the ‘val’ column. Notice here that these two column names are not given in inverted commas. This is because with gather, we were creating two new columns, and so we fed them to R as character vectors (i.e. inside of inverted commas). With the spread function we are naming existing columns and so we give them to R without inverted commas.
SACTN3_tidy1 <- SACTN3 %>%
spread(key = var, value = val)11.2 Separating and uniting
We’ve now covered how to make our dataframes longer or wider depending on their tidiness. Now we will look at how to manage our columns when they contain more (or less) than one variable, but the overall dataframe does not need to be made wider or longer. This is generally the case when one has a column with two variables, or two or more variables are spread out across multiple columns, but there is still only one observation per row. Let’s see some examples to make this more clear.
11.2.1 Separate
If we look at SACTN4a we see that we no longer have a site and src column. Rather these have been replaced by an index column. This is an efficient way to store these data, but it is not tidy because the site and source of each observation have now been combined into one column (variable). Remember, tidy data calls for each of the things known about the data to be its own variable. To re-create our site and src columns we must separate() the index column. First we give R the name of the column we want to separate, in this case index. Next we must say what the names of the new columns will be. Remember that because we are creating new column names we feed these into R within inverted commas. Lastly we should tell R how to separate the index column. If we look at the data we may see that the values we want to split up are separated with ‘/,’ so that is what we give to R. Often times the separate() function is able to guess correctly, but it is better to be explicit.
SACTN4a_tidy <- SACTN4a %>%
separate(col = index, into = c("site", "src"), sep = "/ ")11.2.2 Separating dates using mutate()
Although the date column represents an example of a date type (a kind of data in its own right), one might also want to split this column into its constituent parts, i.e. create separate columns for day, month, and year. In this case we can spread these components of the date vector into three columns using the mutate() function and some functions in the lubridate package (contained within tidyverse).
SACTN_tidy2 <- SACTN4a %>%
separate(col = index, into = c("site", "src"), sep = "/ ") %>%
mutate(day = lubridate::day(date),
month = lubridate::month(date),
year = lubridate::year(date))Note that when the date is split into component parts the data are no longer tidy (see below).
11.2.3 Unite
It is not uncommon that field/lab instruments split values across multiple columns while they are making recordings. I see this most often with date values. Often the year, month, and day values are given in different columns. There are uses for the data in this way, though it is not terribly tidy. We usually want the date of any observation to be shown in just one column. If we look at SACTN4b we will see that there is a year, month, and day column. To unite() them we must first tell R what we want the united column to be labelled, in this case we will use date. We then list the columns to be united, her this is year, month, and day. Lastly we must specify if we want the united values to have a separator between them. The standard separator for date values is ‘-.’
SACTN4b_tidy <- SACTN4b %>%
unite(year, month, day, col = "date", sep = "-")11.3 Joining
We will end this session with the concept of joining two different dataframes. Remember that one of the rules of tidy data is that only one complete dataset is saved per dataframe. This rule then is violated not only when additional data are stored where they don’t belong, but also when necessary data are saved elsewhere. If we look back at SACTN4a and SACTN4b we will see that they are each missing different columns. Were we to join these dataframes together they would complete each other. The tidyverse provides us with several methods of doing this, but we will demonstrate here only the most common technique. The function left_join() is so named because it joins two or more dataframes together based on the matching of columns from the left to the right. It combines values together where it sees that they match up, and adds new rows and columns where they do not.
SACTN4_tidy <- left_join(SACTN4a_tidy, SACTN4b_tidy)R> Joining, by = c("site", "src", "date")As we see above, if we let left_join() do it’s thing it will make a plan for us and find the common columns and match up the values and observations for us as best it can. It then returns a message letting us know what it’s done. That is a pleasant convenience, but we most likely want to exert more control over this process than that. In order to specify the columns to be used for joining we must add one more argument to left_join(). The by argument must be fed a list of column names in inverted commas if we want to specify how to join our dataframes. Not that when we run this it does not produce a message as we have provided enough explicit information that the machine is no longer needing to think for itself.
SACTN4_tidy <- left_join(SACTN4a_tidy, SACTN4b_tidy, by = c("site", "src", "date"))There are also other kinds of joins: see for example also inner_join, right_join, full_join, semi-join, nest_join, and anti_join in the dplyr package contained within tidyverse.
11.4 But why though?
At this point one may be wondering what the point of all of this is. Sure it’s all well and good to see how to tidy one’s data in R, but couldn’t this be done more quickly and easily in MS Excel? Perhaps, yes, with a small dataset. But remember, (for many) the main reason we are learning R is to ensure that we are performing reproducible research. This means that every step in our workflow must be documented. And we accomplish this by writing R scripts, and part of the purpose of these scripts is to ensure that we capture all the steps taken to get the raw data into a neat and tidy format that can unambiguously be read into R in the format that will quicky get us up and running with our analyses and visualisations.
11.5 Session info
installed.packages()[names(sessionInfo()$otherPkgs), "Version"]R> forcats stringr dplyr purrr readr tidyr tibble ggplot2
R> "0.5.1" "1.4.0" "1.0.7" "0.3.4" "1.4.0" "1.1.3" "3.1.2" "3.3.4"
R> tidyverse
R> "1.3.1"